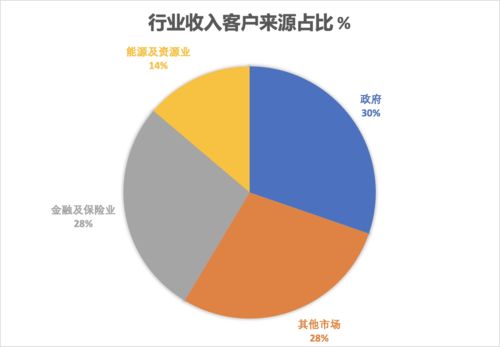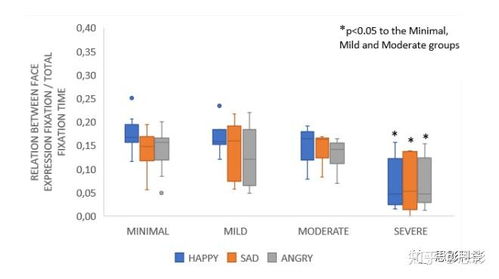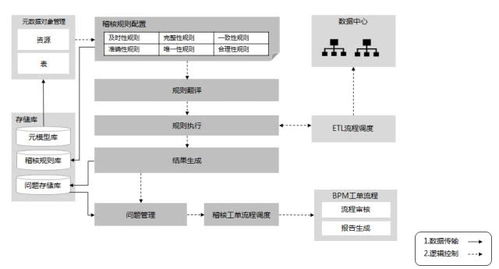
在垂直服務電商領域,數據化運營已成為提升產品競爭力、優化用戶體驗和驅動業務增長的核心引擎。而這一切的基石,正是高效、精準、可靠的數據處理服務。它如同整個數據化運營體系的“中央廚房”,將原始、雜亂的數據原料,加工成可供分析、決策、應用的“美味佳肴”。
一、 數據處理服務的核心價值與定位
垂直服務電商(如在線教育、醫療健康、家政服務、旅游預訂等)具有需求明確、用戶決策路徑長、服務非標化、履約環節復雜等特點。其數據化運營分析不僅關注流量和交易,更深度涉及用戶生命周期價值(LTV)、服務交付質量、供需匹配效率、復購與口碑等維度。因此,數據處理服務在此場景下承擔著關鍵使命:
- 多源異構數據整合:打通App端、Web端、小程序、客服系統、ERP、CRM、第三方平臺(如支付、地圖、評價)等多渠道數據,構建統一的用戶與業務視圖。
- 服務過程數據化:將非標服務的預約、溝通、履約、驗收、評價等環節進行結構化記錄與量化,形成可分析的服務質量指標體系。
- 實時與離線處理并重:既要支持實時監控(如服務訂單狀態、資源調度情況、異常告警),也要進行深度的離線分析(如用戶分群、服務品類趨勢預測、運營活動復盤)。
- 保障數據質量與安全:確保數據的準確性、一致性、及時性,并嚴格遵守數據隱私法規,對敏感信息進行脫敏加密處理。
二、 數據處理服務的關鍵流程與技術棧
一個完整的垂直服務電商數據處理服務通常遵循以下流程,并依托相應的技術棧實現:
- 數據采集與接入:
- 方式:埋點SDK、日志收集、API同步、數據庫直連等。
- 要點:制定統一的數據采集規范,確保關鍵行為(如瀏覽服務詳情、預約咨詢、完成支付、提交評價)被完整捕獲。
- 數據清洗與標準化:
- 任務:處理數據缺失、異常值、格式不一致問題;將非標服務信息(如服務描述、用戶評價文本)通過NLP技術進行標簽化、情感分析等初步結構化。
- 技術:通常使用Spark、Flink等分布式計算框架編寫清洗規則腳本。
- 數據存儲與管理:
- 分層存儲:構建ODS(操作數據層)、DWD(明細數據層)、DWS(匯總數據層)、ADS(應用數據層)等數據倉庫層級。
- 選型:HDFS、Hive、ClickHouse用于海量離線存儲與查詢;Kafka用于實時數據流;Redis、HBase用于高速緩存與查詢;對象存儲用于非結構化數據。
- 數據建模與開發:
- 核心:構建貼合垂直業務的數據模型,如用戶360°畫像模型、服務供給模型、訂單生命周期模型、資源效能模型等。
- 工具:依賴數據開發平臺(如DataWorks、Airflow)進行ETL任務調度、依賴管理與監控。
- 數據服務與應用:
- 輸出形式:通過API、數據報表、可視化儀表盤、實時數據推送等方式,將處理后的數據提供給運營、產品、市場、管理層使用。
- 典型應用:個性化推薦(服務/技師推薦)、動態定價策略、智能客服輔助、服務資源智能調度、運營活動效果分析看板。
三、 面向分析場景的數據處理服務實踐
數據處理服務必須緊密圍繞具體的運營分析場景來設計和優化:
- 用戶增長分析:處理渠道來源、拉新成本、激活轉化漏斗數據,識別高價值渠道與用戶群體。
- 用戶體驗與留存分析:串聯用戶從搜索、比價、咨詢到履約、評價的全鏈路行為數據,分析流失節點與服務痛點。
- 供給端效能分析:處理服務提供者(如老師、醫生、技師)的接單率、服務質量評分、用戶評價等數據,優化供給管理與培訓。
- 商業智能與預測:基于歷史訂單、季節性、市場活動數據,預測不同服務品類的需求趨勢,輔助庫存(服務能力)管理和營銷預算規劃。
四、 挑戰與未來趨勢
挑戰:數據孤島問題在復雜系統架構中依然存在;非標服務的數據化難度高;實時分析與決策對數據處理延遲要求苛刻;數據合規成本日益增加。
趨勢:
1. 實時化與智能化:流批一體數據處理架構成為標配,AI/ML模型被更深度地集成到數據處理管道中,實現實時特征計算與智能預警。
2. 自助化與平民化:通過建設完善的數據中臺與自助分析工具,降低業務人員使用數據的門檻,讓數據更直接地驅動一線運營。
3. 云原生與一體化:基于云平臺的數據湖倉一體解決方案,提供更彈性、更集成、更低運維成本的數據處理能力。
4. 隱私計算應用:在數據融合與聯合分析中,采用聯邦學習、安全多方計算等技術,在保護用戶隱私的前提下挖掘數據價值。
結論
對于垂直服務電商產品而言,卓越的數據處理服務并非簡單的技術后臺,而是數據化運營的“心臟”與“神經中樞”。它通過系統化、工程化的方式,將業務轉化為數據,再將數據轉化為洞察與行動力,最終實現服務體驗的優化、運營效率的提升和商業模式的創新。構建與之匹配的數據處理能力,是垂直服務電商在激烈市場競爭中構筑核心壁壘的關鍵一環。